

What Kind Of Data Required For Machine Learning
What is training data?
In machine learning, grooming data is the information you use to train a machine learning algorithm or model. Training data requires some human involvement to analyze or procedure the data for auto learning apply. How people are involved depends on the type of car learning algorithms you are using and the type of trouble that they are intended to solve.
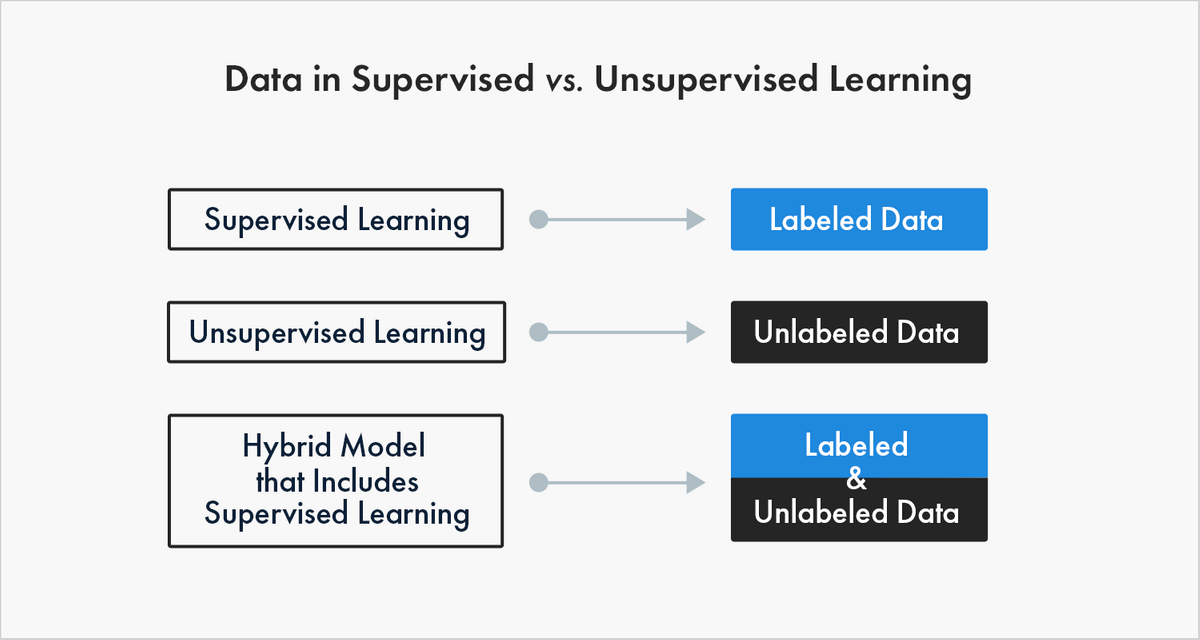
- With supervised learning, people are involved in choosing the data features to exist used for the model. Preparation data must be labeled - that is, enriched or annotated - to teach the car how to recognize the outcomes your model is designed to detect.
- Unsupervised learning uses unlabeled data to observe patterns in the information, such equally inferences or clustering of data points. At that place are hybrid machine learning models that allow you to use a combination of supervised and unsupervised learning.
Training data comes in many forms, reflecting the myriad potential applications of automobile learning algorithms. Training datasets tin include text (words and numbers), images, video, or sound. And they can be available to you in many formats, such as a spreadsheet, PDF, HTML, or JSON. When labeled appropriately, your information can serve every bit footing truth for developing an evolving, performant motorcar-learning formula.
What is labeled data?
Labeled data is annotated to show the target, which is the outcome yous want your motorcar learning model to predict. Data labeling is sometimes called data tagging, note, moderation, transcription, or processing. The process of data labeling involves marking a dataset with key features that volition help railroad train your algorithm. Labeled data explicitly calls out features that you have selected to identify in the data, and that blueprint trains the algorithm to discern the aforementioned blueprint in unlabeled data.
Take, for instance, you are using supervised learning to train a machine learning model to review incoming customer emails and send them to the advisable department for resolution. One outcome for your model could involve sentiment assay - or identifying language that could point a customer has a complaint, so you could make up one's mind to label every example of the words "problem" or "issue" within each email in your dataset.
That, along with other information features yous identify in the process of data labeling and model testing, could assist y'all train the auto to accurately predict which emails to escalate to a service recovery team.
The way data labelers score, or assign weight, to each label and how they manage edge cases also affects the accuracy of your model. You lot may need to find labelers with domain expertise relevant to your use example. As you can imagine, the quality of the data labeling for your training data can determine the performance of your machine learning model.
Enter the human in the loop.
What is human in the loop?
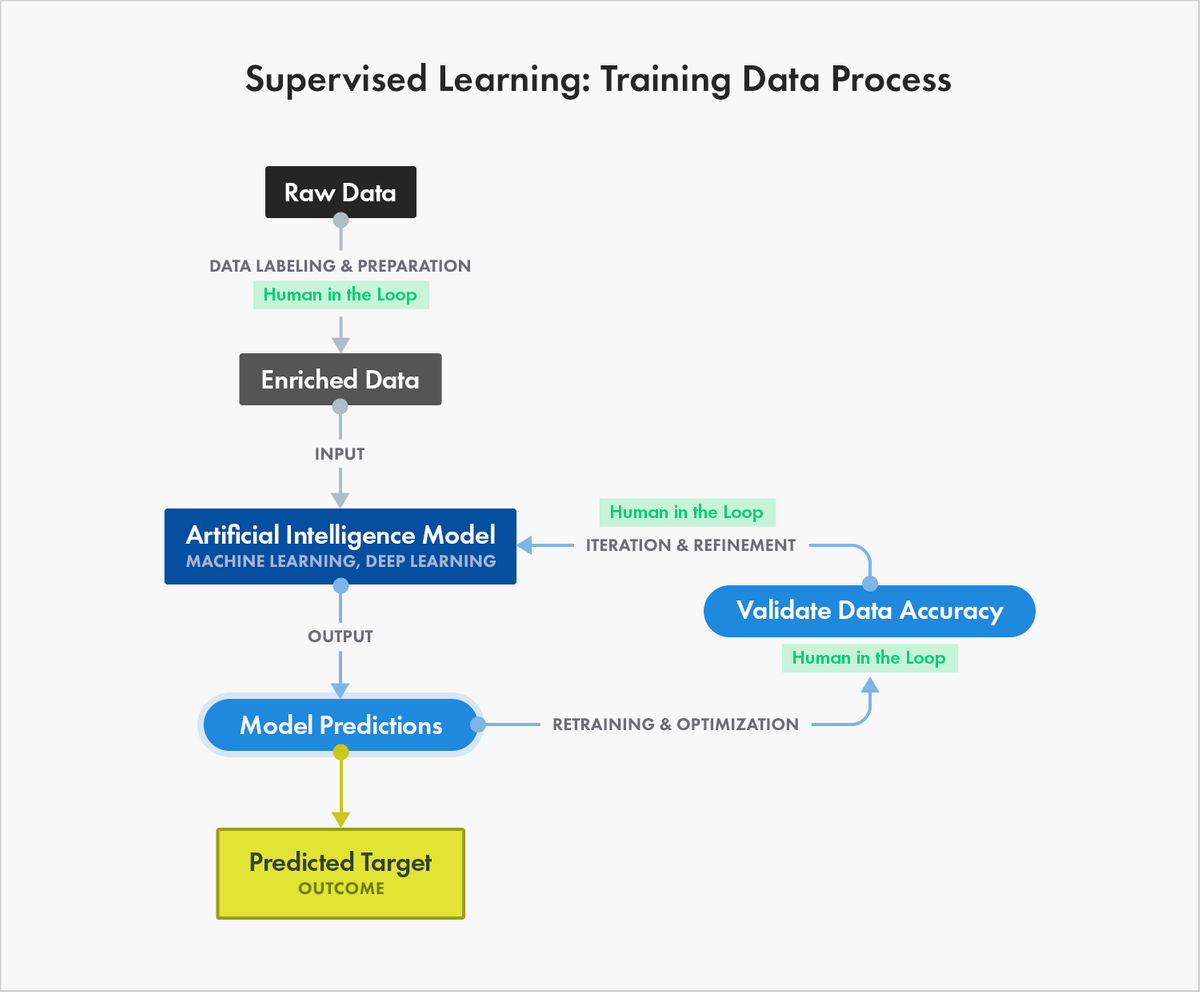
"Man in the loop" applies the judgment of people who work with the information that is used with a machine learning model. When it comes to data labeling, the humans in the loop are the people who get together the data and gear up information technology for use in machine learning.
Gathering the information includes getting access to the raw data and choosing the important attributes of the data that would exist adept indicators of the event yous want your machine learning model to predict.
This is an of import step considering the quality and quantity of information that y'all gather will determine how adept your predictive model could be. Preparing the information means loading it into a suitable place and getting it ready to be used in machine learning training.
Consider datasets that include point-cloud data from lidar-derived images that must be labeled to train motorcar learning models that operate autonomous vehicle (AV) systems. People use advanced digital tools, such as 3-D cuboid annotation software, to annotate features within that data, such every bit the occurrence, location, and size of every cease sign in a single image.
This is not a 1-and-washed approach, because with every test, you will uncover new opportunities to improve your model. The people who piece of work with your data play a critical part in the quality of your preparation information. Every incorrect characterization tin have an event on your model's operation.
How is training information used in machine learning?
Dissimilar other kinds of algorithms, which are governed past pre-established parameters that provide a sort of "recipe," automobile learning algorithms improve through exposure to pertinent examples in your training data.
The features in your preparation data and the quality of labeled training data will make up one's mind how accurately the machine learns to place the outcome, or the reply you want your machine learning model to predict.
For example, yous could railroad train an algorithm intended to identify suspicious credit carte charges with cardholder transaction data that is accurately labeled for the data features, or attributes, you decide are primal indicators for fraud.
The quality and quantity of your training data determine the accurateness and performance of your machine learning model. If you trained your model using training information from 100 transactions, its operation probable would stake in comparison to that of a model trained on information from 10,000 transactions. When it comes to the diverseness and volume of training data, more is usually improve – provided the data is properly labeled.
"Every bit data scientists, our time is all-time spent plumbing equipment models. So we appreciate it when the information is well structured, labeled with high quality, and fix to be analyzed," says Lander Analytics Founder and Principal Information Scientist Jared P. Lander. His full-service consulting business firm helps organizations leverage data scientific discipline to solve real-world challenges.
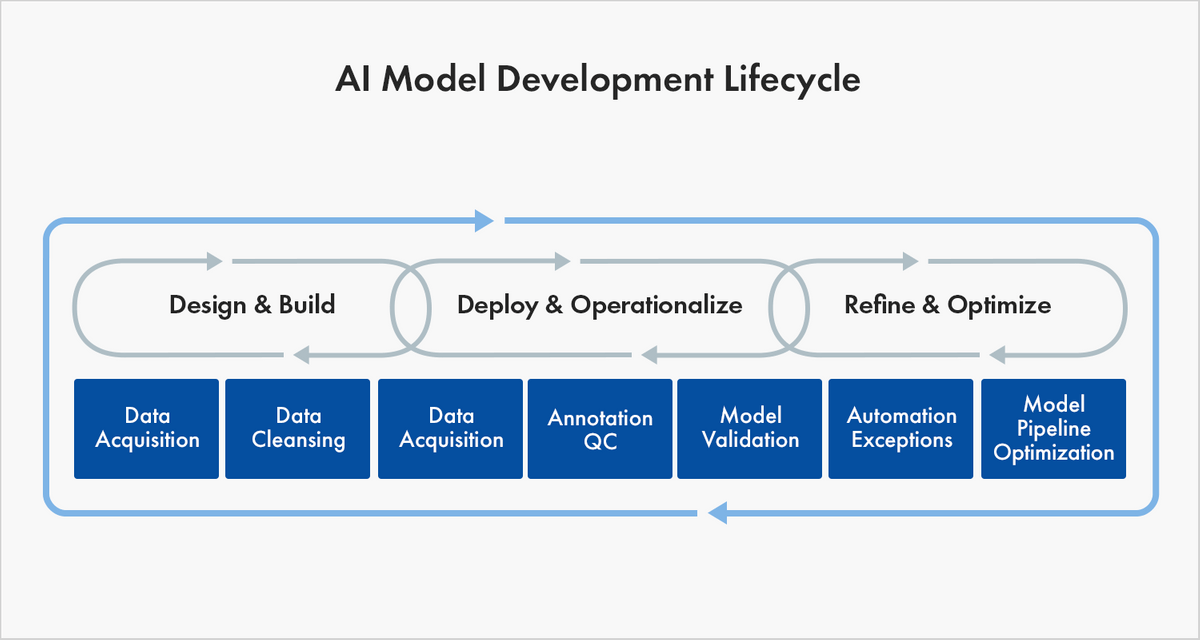
Grooming information is used non but to train but to retrain your model throughout the AI evolution lifecycle. Preparation data is not static: as real-world conditions evolve, your initial training dataset may be less accurate in its representation of footing truth as fourth dimension goes on, requiring you to update your training data to reflect those changes and retrain your model.
What is the divergence between training information and testing data?
It's of import to differentiate between training and testing data, though both are integral to improving and validating machine learning models. Whereas training data "teaches" an algorithm to recognize patterns in a dataset, testing information is used to assess the model'south accuracy.
More specifically, training data is the dataset y'all utilize to train your algorithm or model and so it can accurately predict your consequence. Validation data is used to assess and inform your choice of algorithm and parameters of the model you are building. Test data is used to measure out the accurateness and efficiency of the algorithm used to train the automobile - to meet how well it can predict new answers based on its training.
Take, for example, a machine learning model intended to determine whether or not a human being is pictured in an image. In this case, grooming data would include images, tagged to betoken the photo includes the presence or absence of a person. After feeding your model this grooming data, y'all would then unleash it on unlabeled exam data, including images with and without people. The algorithm's operation on test information would then validate your training approach – or bespeak a need for more or dissimilar training data.
How can I get training data?
You can use your ain data and label it yourself, whether you use an in-house team, crowdsourcing, or a data labeling service to exercise the work for yous. You besides tin can purchase training data that is labeled for the data features you determine are relevant to the machine learning model yous are developing.
Auto-labeling features in commercial tools tin help speed upwards your team, merely they are not consistently accurate plenty to handle production data pipelines without human being review. Dataloop, Hivemind, and V7 Labs accept machine-labeling features in their enrichment tools.
Your machine learning employ instance and goals will dictate the kind of data you lot need and where you lot can get it. If y'all are using tongue processing (NLP) to teach a machine to read, empathise, and derive meaning from linguistic communication, you volition need a significant amount of text or sound information to train your algorithm.
Y'all would need a different kind of training data if you are working on a computer vision project to teach a machine to recognize or gain understanding of objects that can be seen with the human eye. In this instance, yous would demand labeled images or videos to train your machine learning model to "meet" for itself.
In that location are many sources that provide open up datasets, such every bit Google, Kaggle and Information.gov. Many of these open datasets are maintained by enterprise companies, authorities agencies, or bookish institutions.
How much preparation data do I need?
At that place'south no clear reply - no magical mathematical equation to reply this question - but more data is ameliorate. The amount of preparation information you demand to create a automobile learning model depends on the complication of both the trouble you seek to solve and the algorithm you develop to practice it. Ane fashion to observe how much training data you volition demand is to build your model with the data you lot accept and see how it performs.

What Kind Of Data Required For Machine Learning,
Source: https://www.cloudfactory.com/training-data-guide
Posted by: martinguill2000.blogspot.com
0 Response to "What Kind Of Data Required For Machine Learning"
Post a Comment