

Steps Required For Selecting The Right Machine Learning Algorithm?
How to Choose the Right Machine Learning Algorithm for Your Application
Heed to your information, follow your goals…

When I offset started learning and practicing data scientific discipline and machine learning, I would look up resource and tutorials to implement and utilise a specific car learning algorithm.
The internet is full of materials that teach y'all how to use an algorithm, how it works, and how to employ to your data.
Even so, when I started building my projects, I would accept a long fourth dimension trying to decide which algorithm to use.
Come across, what well-nigh of the articles on how to utilize a specific algorithm miss are when to use this algorithm and how to cull the best algorithm for your information.
In this article, I will try to go over the process I follow in choosing the all-time machine learning algorithm for a specific projection.
Earlier we start, let'due south first become through the types of machine learning algorithms.
Types of automobile learning algorithms
Auto learning algorithms can be categorized broadly into three main categories:
Supervised learning
In Supervised learning, the algorithm builds a mathematical model from the training information, which has labels for both the inputs and output. Data nomenclature and regression algorithms are considered supervised learning.
Unsupervised learning
In Unsupervised learning, the algorithm builds a model on information that only has the input features merely no labels for output. The models then are trained to look for some structure within the data. Clustering and southegmentation are examples of unsupervised learning algorithms.
Reinforcement learning
In Reinforcement learning, the model learns to perform a job past performing a ready of deportment and decisions information technology improvises by itself and then learn from the feedback of those deportment and decisions. Monte Carlo is an example of reinforcement learning algorithms.

Choosing the right algorithm
So, you know the different algorithms types, yous know how they differ, and you lot know how to use them. The question at present is when to use each of these algorithms?
To answer this question, we need to consider 4 aspects of the problem we are trying to solve:
№1: The Data
Knowing your information is the commencement and foremost stride of deciding on an algorithm. Before you lot start thinking most the dissimilar algorithms, you demand to familiarize yourself with your information. A uncomplicated way to do that is to visualize the data and try to detect patterns within it, try to observe it's behavior, and, most importantly of all, its size.
Knowing the critical information nigh your information will help you make an initial decision on an algorithm.
- The size of data: Some algorithms perform better with larger information than others. For example, for small grooming datasets, algorithms with high bais/ low variance classifiers volition piece of work better than low bias/ high variance classifiers. And so, for small-scale preparation data, Naïve Bayes volition perform better than kNN.
- The characteristics of data: This ways how your data is formed. Is your data linear? And then mayhap a linear model will fit it all-time, such as regressions — linear and logistic — or SVM (back up vector motorcar). However, if your data is more complex, and so you need an algorithm similar random wood.
- The behavior of data: Are your features sequential or chained? If it is sequential? Are you trying to forecast the weather condition or the stock market place? Then it would be best if you used an algorithm that matches that, such every bit Markov models and decision copse.
- The type of data: Y'all can either categorize your input or output data. If your input data is labeled, and so use a supervised learning algorithm; if not, information technology'due south probably an unsupervised learning problem. On the other hand, if your output data is numeric, then use regression, but if it's a gear up of groups, then it's a clustering problem.
№ii: The Accuracy
Now that you have studied your information, analyzed its type, characteristics, and size, you demand to enquire yourself how much does accurateness matter to the problem you lot're trying to solve?
The accurateness of a model refers to its ability to predict an respond from a given observation set close to the right response for that ascertainment set.
Sometimes getting an accurate answer is not necessary for our target awarding. If an approximation is good enough, we can cut our training and processing fourth dimension significantly by choosing an estimate model. Approximate methods avoid or don't perform overfitting or the information, such every bit linear regression on not-so-linear information.
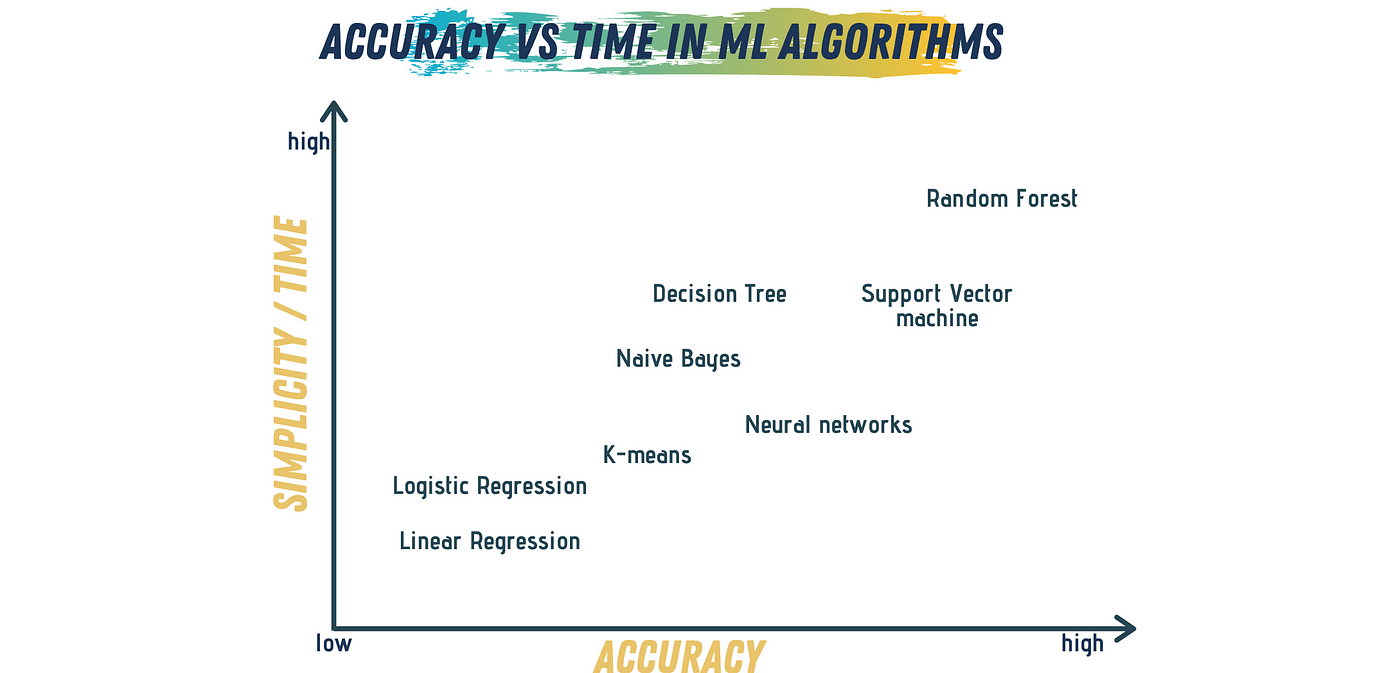
№3: The Speed
Often, accuracy and speed stand on opposite sides; you need to make some trade-offs between the two when deciding on an algorithm. Higher accuracy typically ways more extended preparation and processing times.
Algorithms like Naïve Bayes and Linear and Logistic regression are easy to understand and implement and, hence they accept fast execution. More complex algorithms like SVM, Neural networks, and random forests, need a much longer time to procedure and train data.
And so, which is of more value to your project? Accurateness or time? If it'south time, going with a simpler algorithm will be better, while if accuracy is the well-nigh important thing, then choosing a more complex algorithm will work ameliorate for your project.
№4: Features and parameters
The parameter of your problems is numbers that volition bear on how the algorithm yous will choose to behave. Parameters are factors such every bit mistake tolerance or the number of iterations, or options between variants of how the algorithm behaves. The fourth dimension needed to train and process your information is frequently related to how many parameters you have.
The time required to process and train a model increases exponentially with the number of parameters. However, having many parameters typically indicates that an algorithm is more flexible.
In automobile learning — or information science, in full general, a feature is a quantifiable variable of the trouble you are trying to analyze.
Having a large number of features can slow down some algorithms, making preparation time quite long. If your problem has many features, then using an algorithm such every bit SVM, which is well suited to applications with a high number of features, is the best way to go.
Final thoughts
Many factors control the process of choosing an algorithm. We can mainly divide your decision criteria into 2 sections, data-related aspects, and trouble-related aspects.
The size, behavior, characteristics, and type of your information tin can requite y'all the initial thought of what algorithm to utilise. Once you lot get this initial decision, different aspects of your problem volition help you decide on a final conclusion.

Finally , e'er think 2 things:
- Better data leads to amend results than complex algorithms; if y'all tin accomplish like results using a much simpler algorithm, opt for simplicity.
- You can improve the accuracy of an algorithm by sacrificing more than time on processing and training the data. Make the determination based on the priority for your specific project.
E'er listen to the story your data is trying to say, whiling post-obit the goals of your project.

Source: https://towardsdatascience.com/how-to-choose-the-right-machine-learning-algorithm-for-your-application-1e36c32400b9
Posted by: martinguill2000.blogspot.com
0 Response to "Steps Required For Selecting The Right Machine Learning Algorithm?"
Post a Comment